Apple’s new model recreates 3D objects with realistic lighting effects
Apple researchers have developed an AI model that reconstructs a 3D object from a single image, while keeping reflections, highlights, and other effects consistent across different viewing angles. Here are the details.
A little context
Although the concept of latent space in machine learning is not really new, it has become more popular than ever in recent years, with the explosion of AI models based on transformer architecture and, more recently, global models.
In short (and at the risk of misrepresenting the big picture), “hidden space,” or “embedded space,” are terms that describe what happens there:
- Boil the knowledge in showing the numbers of their minds;
- Arrange these numbers in a multidimensional space, which makes it possible to calculate the distances between them in different widths.
If that still sounds too absurd, one classic example is to find the mathematical representation of the token “king”, subtract the mathematical representation of the token “man”, add the mathematical representation of the token “female”, and you will end up with the general multi-dimensional region of the token “queen”.
In practical terms, storing information as a mathematical representation in a hidden place makes it faster and less expensive than mathematics to measure distances between them and estimate the probabilities of what to do.
Here’s a short video explaining the hidden area using a different analogy:
Although the examples above focus on storing text in a hidden location, the same idea can be applied to many other types of data. Which brings us to Apple’s lesson.
LiTo: Surface Light Field Tokenization
In Apple’s new research, titled LiTo: Surface Light Field Tokenization, the researchers “propose a latent 3D representation that jointly combines geometric modeling and perspective-based visualization.”
In other words, they created a way to represent, in a subtle way, not only how to reconstruct a three-dimensional object, but also how the light interacting with it should appear from different angles.
As they explain:
Most previous works focus on reconstructing 3D geometry or predicting different views that are independent of the view, and thus it is difficult to capture the realistic effects that depend on the view. Our method enables deep RGB images to provide samples of the surface light field. By encoding random samples of this surface light field into a compact set of hidden vectors, our model learns to represent both geometry and appearance within a 3D hidden space. This display reproduces view-dependent effects such as special highlights and Fresnel reflections under complex illumination.
In addition, the researchers were able to train the model to be able to do all that with a single image, rather than the more common methods that require images from different angles to enable 3D reconstruction.
Although the whole method is highly technical and is explained in detail in the study, the main idea is actually simple, once you understand how the hidden area works:
- First, the encoder compresses the information about the object into a coherent representation in the latent space. So, instead of storing all the physical information, it learns a mathematical summary of the object’s shape and how the light interacts with its environment.
- Then, the decoder does the opposite. It reconstructs the full 3D object from that composite representation, generating both the geometry and the representation of how lighting effects, such as brightness and contrast, should appear at different viewing angles.
Training LiTo
To train the model, the researchers selected thousands of objects presented at 150 different viewing angles, and 3 lighting conditions.
Then, instead of feeding all that information directly into the model, the system randomly selected subsets of these samples and compressed them into a latent representation.
Next, the decoder was trained to reconstruct the full object and its appearance under different angles and lighting conditions, from that small data set.

During training, the system learned an implicit representation that captures both the geometry of the object, and how its appearance changes depending on the viewing angle.
Once that’s done, they train yet another model that takes a single image of an object and predicts the associated implicit representation. Next, the decoder reconstructs the complete 3D object, including how its appearance changes as the viewing angle varies.
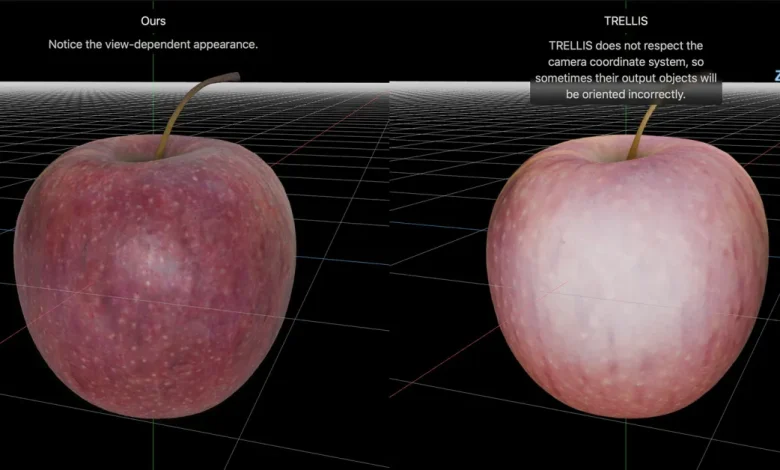
Here are a few reconstruction comparisons between LiTo and a model called TRELLIS, as published by Apple on the project page:
Be sure to check out the project page, where you can also upload a side-by-side interactive comparison between LiTo and TRELLIS, as seen in the featured image of this post.
And for the full tutorial, follow this link.
It’s worth checking out on Amazon
![]()
![]()
FTC: We use auto affiliate links to earn income. More.




